
|
|
|
I'm a Ph.D. candidate at Duke University working on ML/NLP. I'm fortunate to be advised by Prof. Lawrence Carin. My Ph.D. research interests focus on deep learning-based Natural Language Processing (NLP). In particular, I’m interested in incorporating classical NLP ideas on to deep learning frameworks to aid tasks like machine translation, natural language understanding, and reasoning. ~ Email | Google Scholar | Github | LinkedIn | ~ |

|
May '20 - Aug '20 NLP research internship focusing on topic modeling, summarization. |

|
Sep '20 - Dec '20 Research intern at Google research. Worked on task weighting for multi-task learning for NLP. |

|
June '21 - Aug '21 Worked on Domain generalization, Semantic parsing. |
|
|
Oct '21 - Dec '21 NLP Applied Scientist Intern |
|
Arxiv Preprint [preprint] Biases in culture, gender, ethnicity, etc. have existed for decades and have affected many areas of human social interaction. These biases have been shown to impact machine learning (ML) models, and for natural language processing (NLP), this can have severe consequences for downstream tasks. Mitigating gender bias in information retrieval (IR) is important to avoid propagating stereotypes. In this work, we employ a dataset consisting of two components: (1) relevance of a document to a query and (2) "gender" of a document, in which pronouns are replaced by male, female, and neutral conjugations. We definitively show that pre-trained models for IR do not perform well in zero-shot retrieval tasks when full fine-tuning of a large pre-trained BERT encoder is performed and that lightweight fine-tuning performed with adapter networks improves zero-shot retrieval performance almost by 20% over baseline. We also illustrate that pre-trained models have gender biases that result in retrieved articles tending to be more often male than female. We overcome this by introducing a debiasing technique that penalizes the model when it prefers males over females, resulting in an effective model that retrieves articles in a balanced fashion across genders. |

|
International Conference on Information and Knowledge Management '22. [preprint] Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. For instance, in named entity recognition (NER), numbers are not treated as an entity with distinct tags. In this work, we attempt to tap the potential of state-of-the-art language models and transfer their ability to boost performance in related downstream tasks dealing with numbers. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering, using joint embeddings, outperforming the BERT and RoBERTa baseline classification. |
|
The 2021 Conference on Empirical Methods in Natural Language Processing. [Paper] It has been shown that training multi-task models with auxiliary tasks can improve the target task quality through cross-task transfer. However, the importance of each auxiliary task to the primary task is likely not known a priori. While the importance weights of auxiliary tasks can be manually tuned, it becomes practically infeasible with the number of tasks scaling up. To address this, we propose a search method that automatically assigns importance weights. We formulate it as a reinforcement learning problem and learn a task sampling schedule based on the evaluation accuracy of the multi-task model. Our empirical evaluation on XNLI and GLUE shows that our method outperforms uniform sampling and the corresponding single-task baseline. |
|
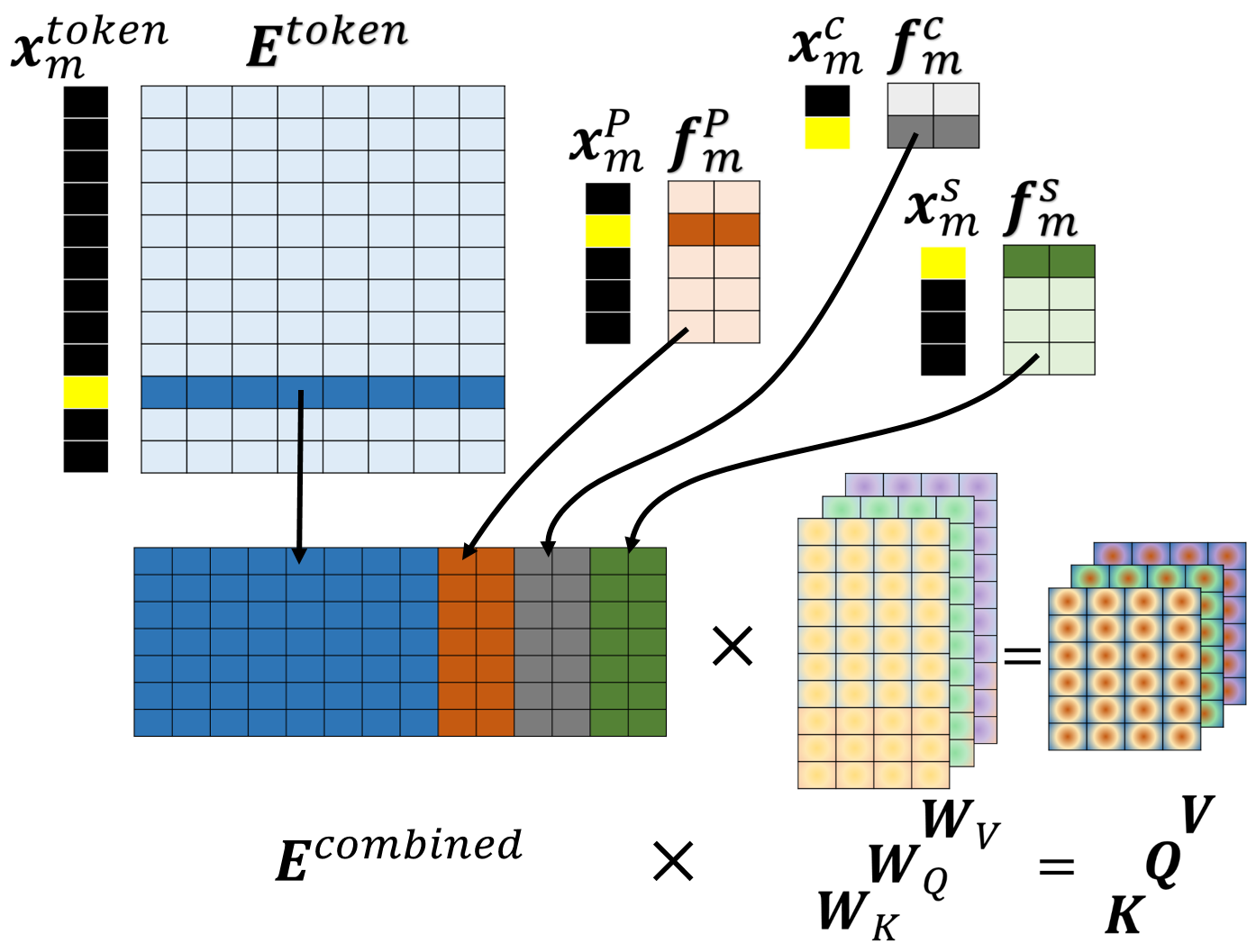
International Conference on Information and Knowledge Management. [Paper] Attention-based deep learning models have demonstrated significant improvement over traditional algorithms in several NLP tasks. The Transformer, for instance, is an illustrative example that generates abstract representations of tokens that are input to an encoder based on their relationships to all tokens in a sequence. While recent studies have shown that such models are capable of learning syntactic features purely by seeing examples, we hypothesize that explicitly feeding this information to deep learning models can significantly enhance their performance in many cases. Leveraging syntactic information like part of speech (POS) may be particularly beneficial in limited-training-data settings for complex models such as the Transformer. In this paper, we verify this hypothesis by infusing syntactic knowledge into the Transformer. We find that this syntax-infused Transformer achieves an improvement of 0.7 BLEU when trained on the full WMT’14 English to German translation dataset and a maximum improvement of 1.99 BLEU points when trained on a fraction of the dataset. In addition, we find that the incorporation of syntax into BERT fine-tuning outperforms BERTBASE on all downstream tasks from the GLUE benchmark, including an improvement of 0.8% on CoLA. |
|
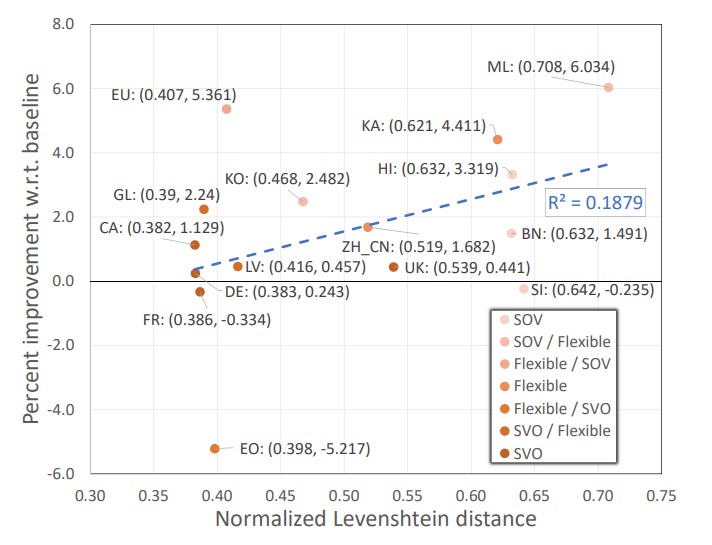
Arxiv Preprint. [Preprint] Neural machine translation (NMT) systems aim to map text from one language into another. While there are a wide variety of applications of NMT, one of the most important is translation of natural language. A distinguishing factor of natural language is that words are typically ordered according to the rules of the grammar of a given language. Although many advances have been made in developing NMT systems for translating natural language, little research has been done on understanding how the word ordering of and lexical similarity between the source and target language affect translation performance. Here, we investigate these relationships on a variety of low-resource language pairs from the OpenSubtitles2016 database, where the source language is English, and find that the more similar the target language is to English, the greater the translation performance. In addition, we study the impact of providing NMT models with part of speech of words (POS) in the English sequence and find that, for Transformer-based models, the more dissimilar the target language is from English, the greater the benefit provided by POS.. |
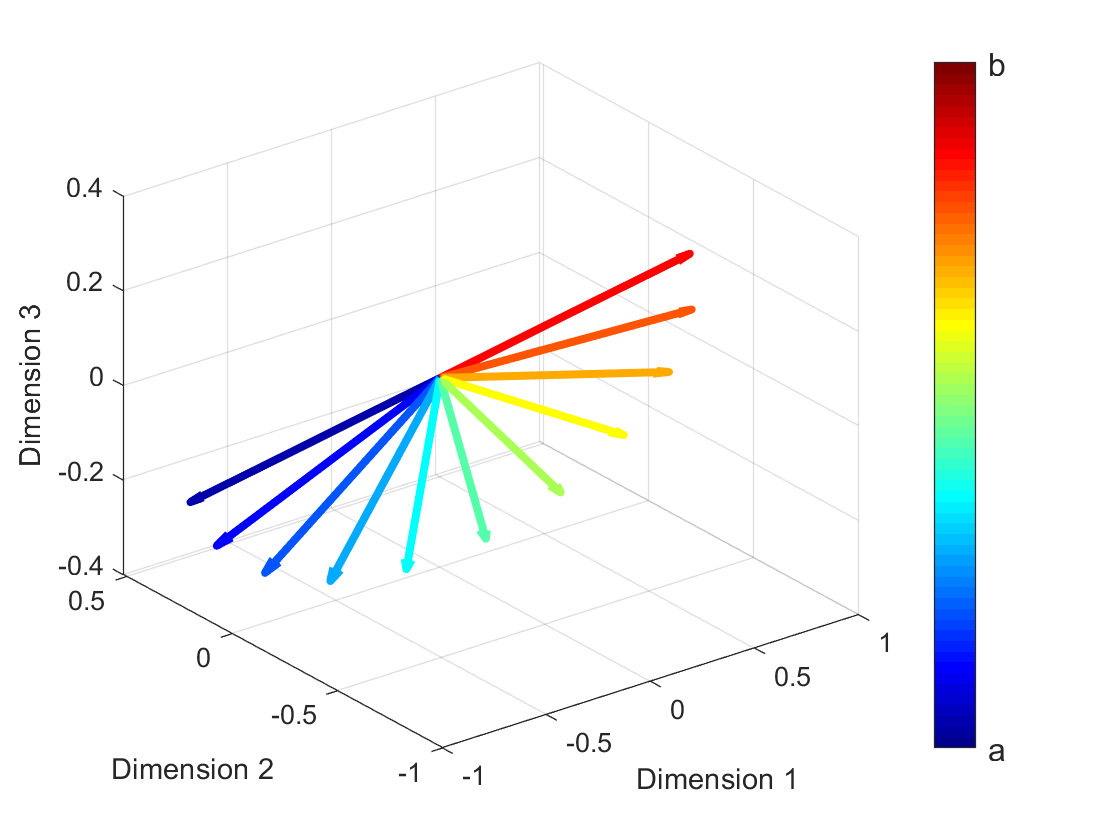
|
The 2020 Conference on Empirical Methods in Natural Language Processing. [Paper] Word embedding models are typically able to capture the semantics of words via the distributional hypothesis, but fail to capture the numerical properties of numbers that appear in the text. This leads to problems with numerical reasoning involving tasks such as question answering. We propose a new methodology to assign and learn embeddings for numbers. Our approach creates Deterministic, Independent-of-Corpus Embeddings (the model is referred to as DICE) for numbers, such that their cosine similarity reflects the actual distance on the number line. DICE outperforms a wide range of pre-trained word embedding models across multiple examples of two tasks:(i) evaluating the ability to capture numeration and magnitude; and (ii) to perform list maximum, decoding, and addition. We further explore the utility of these embeddings in downstream tasks, by initializing numbers with our approach for the task of magnitude prediction. We also introduce a regularization approach to learn model-based embeddings of numbers in a contextual setting. |
|
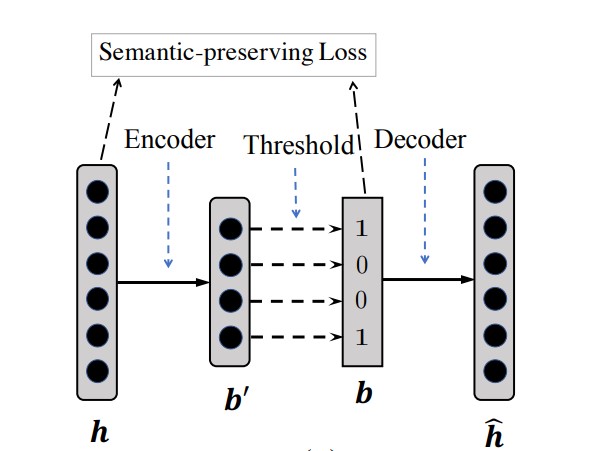
The 2019 Conference on Association for Computational Linguistics. [Paper] Vector representations of sentences, trained on massive text corpora, are widely used as generic sentence embeddings across a variety of NLP problems. The learned representations are generally assumed to be continuous and real-valued, giving rise to a large memory footprint and slow retrieval speed, which hinders their applicability to low-resource (memory and computation) platforms, such as mobile devices. In this paper, we propose four different strategies to transform continuous and generic sentence embeddings into a binarized form, while preserving their rich semantic information. The introduced methods are evaluated across a wide range of downstream tasks, where the binarized sentence embeddings are demonstrated to degrade performance by only about 2% relative to their continuous counterparts, while reducing the storage requirement by over 98%. Moreover, with the learned binary representations, the semantic relatedness of two sentences can be evaluated by simply calculating their Hamming distance, which is more computational efficient compared with the inner product operation between continuous embeddings. Detailed analysis and case study further validate the effectiveness of proposed methods. |
|
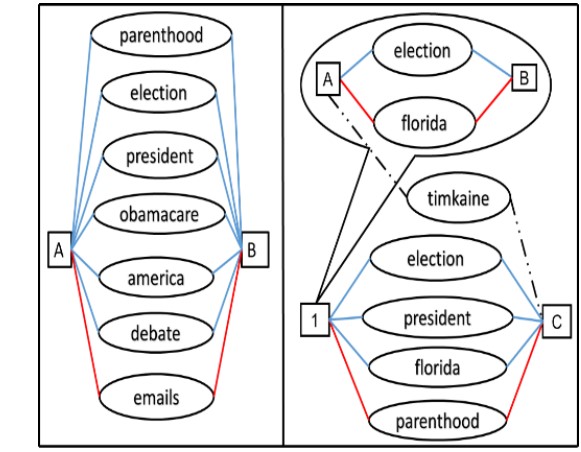
The 2017 International Conference on Social Informatics. [Paper] The social media craze is on an ever increasing spree, and people are connected with each other like never before, but these vast connections are visually unexplored. We propose a methodology Twigraph to explore the connections between persons using their Twitter profiles. First, we propose a hybrid approach of recommending social media profiles, articles, and advertisements to a user. The profiles are recommended based on the similarity score between the user profile, and profile under evaluation. The similarity between a set of profiles is investigated by finding the top influential words thus causing a high similarity through an Influence Term Metric for each word. Then, we group profiles of various domains such as politics, sports, and entertainment based on the similarity score through a novel clustering algorithm. The connectivity between profiles is envisaged using word graphs that help in finding the words that connect a set of profiles and the profiles that are connected to a word. Finally, we analyze the top influential words over a set of profiles through clustering by finding the similarity of that profiles enabling to break down a Twitter profile with a lot of followers to fine level word connections using word graphs. The proposed method was implemented on datasets comprising 1.1 M Tweets obtained from Twitter. Experimental results show that the resultant influential words were highly representative of the relationship between two profiles or a set of profiles. |
This template is a modification to Jon Barron's website